在现代分布式系统中,可观测性已成为保障服务稳定运行的关键基础设施。OpenTelemetry 作为 CNCF 孵化的可观测性标准,提供了统一的 API 和 SDK 来生成、采集和传输遥测数据(Metrics、Logs、Traces)。
OpenTelemetry Collector 作为数据采集架构的核心组件,在数据源与存储后端之间提供了灵活的解耦层。本文将深入解析 Collector 的架构设计、可靠性机制,深入探讨 WAL (Write-Ahead Log) 模块的实现原理,并分享我们针对 WAL 元数据一致性问题的工程实践与优化成果。

为什么需要 Collector?
Collector 在可观测性架构中承担着数据中枢的角色,带来以下核心价值:
职责分离与解耦
开发侧:专注业务逻辑与埋点实现,无需关注数据传输、格式转换等基础设施细节。应用程序仅需配置单一的 Collector 端点。
运维侧:独立管理整条观测数据链路,包括数据处理规则、路由策略、后端选型等,无需变更应用代码或重启服务。
集中化配置管理
应用侧配置大幅简化——只需指向 Collector 的地址。完整的数据处理链路配置(采样策略、过滤规则、后端路由等)集中在 Collector 层统一管理。
当需要调整配置或排查问题时,运维团队只需操作 Collector 配置,避免了配置碎片化分散在成百上千个应用实例中的复杂性。
应用性能保护
将数据批处理、压缩、格式转换等资源密集型操作卸载到独立的 Collector 进程,释放应用进程的 CPU 和内存资源,降低可观测性采集对核心业务的性能影响。
Collector 架构解析
Pipeline
Pipeline 定义了数据从接收到导出的完整处理链路。单个 Collector 实例可配置多条相互独立的 Pipeline,每条 Pipeline 由三类核心组件构成。
--- title: Pipeline 数据流 --- flowchart LR R1(Receiver 1) --> P1[Processor 1] R2(Receiver 2) --> P1 RM(...) ~~~ P1 RN(Receiver N) --> P1 P1 --> P2[Processor 2] P2 --> PM[...] PM --> PN[Processor N] PN --> FO((fan-out)) FO --> E1[[Exporter 1]] FO --> E2[[Exporter 2]] FO ~~~ EM[[...]] FO --> EN[[Exporter N]]
Receiver:数据入口
Receiver 监听指定端口,接收各种来源的遥测数据。
常见 Receiver:
- OTLP:OpenTelemetry 原生协议
- Jaeger:Jaeger 追踪数据
- Prometheus:Prometheus 指标抓取
- FluentBit:日志采集
配置示例:
receivers:
otlp:
protocols:
grpc:
endpoint: 0.0.0.0:4317
http:
endpoint: 0.0.0.0:4318
jaeger:
protocols:
grpc:
endpoint: 0.0.0.0:14250
Processor:数据处理
Processor 对流经 Pipeline 的数据进行转换和处理。
核心 Processor 类型:
| Processor | 用途 | 典型场景 |
|---|---|---|
batch | 批量聚合 | 提升导出效率,减少网络调用 |
filter | 数据过滤 | 丢弃调试数据,降低存储成本 |
attributes | 属性操作 | 添加环境标签,移除敏感信息 |
resource | 资源标记 | 统一资源标识,便于查询分组 |
probabilistic_sampler | 概率采样 | 在高流量下控制数据量 |
配置示例:
processors:
# 批量聚合,减少网络调用
batch:
timeout: 10s
send_batch_size: 1024
# 过滤调试级别的追踪
filter:
traces:
span:
- 'attributes["debug"] == true'
# 添加环境标签
resource:
attributes:
- key: environment
value: production
action: upsert
Exporter(数据导出)
将处理完成的数据发送到后端存储或分析系统。
- 支持多种后端:Prometheus、Jaeger、Zipkin、Elasticsearch、Kafka 等
- 可同时导出至多个后端,实现数据多副本
- 内置重试、超时、熔断等可靠性机制
配置示例:
exporters:
# 发送到 OTLP 后端
otlp:
endpoint: backend.example.com:4317
tls:
insecure: false
retry_on_failure:
enabled: true
initial_interval: 5s
max_interval: 30s
sending_queue:
enabled: true
storage: file_storage
# 同时发送到 Prometheus
prometheus:
endpoint: 0.0.0.0:8889
# 本地调试输出
logging:
loglevel: debug
部署模式
Collector 支持灵活的部署拓扑,根据场景需求选择合适的模式。
Agent 模式
作为本地代理与应用程序紧密耦合,可基于不同基础设施形态部署:
- Agent Binary:作为虚拟机/物理机守护进程 (systemd/supervisor) 运行
- Agent Sidecar:作为辅助容器与应用容器共享 Kubernetes Pod 生命周期
- Agent DaemonSet:在每个 Node 上运行单个实例,收集 Kubernetes 节点上所有 Pod 的数据
职责定位:快速、低延迟地收集本地数据并转发,通常仅执行轻量级处理(如基础过滤、批处理)。
flowchart LR
subgraph S1 ["#nbsp;"]
subgraph S2 ["#nbsp;"]
subgraph VM [VM]
PR["Process [SDK]"] -->|Push| AB[Agent Binary]
AB -->|Config| PR
end
subgraph K8s-pod [K8s Pod]
AC["App Container [SDK]"] --> AS[Agent Sidecar]
AS --> AC
end
subgraph K8s-node [K8s Node]
subgraph Pod1 [Pod]
APP1[App] ~~~ APP2[App]
end
subgraph Pod2 [Pod]
APP3[App] ~~~ APP4[App]
end
subgraph Pod3 [Pod]
APP5[App] ~~~ APP6[App]
end
subgraph AD [Agent DaemonSet]
end
APP1 --> AD
APP2 --> AD
APP4 --> AD
APP6 --> AD
end
end
subgraph Backends ["#nbsp;"]
AB --> BE[Backend]
AS --> PRM[Prometheus]
AS --> JA[Jaeger]
AD --> JA
end
end
class S2 noLines;
class VM,K8s-pod,K8s-node,Pod1,Pod2,Pod3,Backends withLines;
class PR,AB,AC,AS,APP1,APP2,APP3,APP4,APP5,APP6,AD,BE,PRM,JA nodeStyle
classDef noLines stroke:#fff,stroke-width:4px,color:#000000;
classDef withLines fill:#fff,stroke:#4f62ad,color:#000000;
classDef nodeStyle fill:#e3e8fc,stroke:#4f62ad,color:#000000;
Gateway 模式
作为独立的服务层部署,可水平扩展以支撑大规模数据处理。
职责定位:
- 聚合来自多个 Agent、SDK 或其他数据源的数据流
- 执行集中式的复杂数据处理(高级采样、数据脱敏、协议转换)
- 统一管理导出策略与后端路由
- 提供高可用与数据可靠性保障的关键层
flowchart LR
subgraph S1 ["#nbsp;"]
subgraph S2 ["#nbsp;"]
subgraph S3 ["#nbsp;"]
subgraph VM [VM]
PR["Process [SDK]"]
end
subgraph K8s-pod [K8s Pod]
AC["App Container [SDK]"]
end
subgraph K8s-node [K8s Node]
subgraph Pod1 [Pod]
APP1[App] ~~~ APP2[App]
end
subgraph Pod2 [Pod]
APP3[App] ~~~ APP4[App]
end
subgraph Pod3 [Pod]
APP5[App] ~~~ APP6[App]
end
subgraph AD [Agent DaemonSet]
end
APP1 --> AD
APP2 --> AD
APP4 --> AD
APP6 --> AD
end
end
subgraph S4 ["#nbsp;"]
PR --> OTEL["Collector Gateway"]
AC --> OTEL
AD --> OTEL
OTEL ---> BE[Backend]
end
end
subgraph S5 ["#nbsp;"]
subgraph S6 ["#nbsp;"]
JA[Jaeger]
end
subgraph S7 ["#nbsp;"]
PRM[Prometheus]
end
end
JA ~~~ PRM
OTEL --> JA
OTEL --> PRM
end
class S1,S3,S4,S5,S6,S7 noLines;
class VM,K8s-pod,K8s-node,Pod1,Pod2,Pod3 withLines;
class S2 lightLines
class PR,AC,APP1,APP2,APP3,APP4,APP5,APP6,AD,OTEL,BE,JA,PRM nodeStyle
classDef noLines stroke-width:0px,color:#000000;
classDef withLines fill:#fff,stroke:#4f62ad,color:#000000;
classDef lightLines stroke:#acaeb0,color:#000000;
classDef nodeStyle fill:#e3e8fc,stroke:#4f62ad,color:#000000;
Collector 可靠性机制
为最大限度降低数据丢失风险,Collector 提供了三层递进式的可靠性保障机制。
第一层:内存缓冲队列
工作原理:Exporter 发送数据前,先将批次暂存于内存队列。当下游后端不可用时,启用带指数退避的重试机制。
适用场景:下游服务短暂故障或网络抖动
局限性:
- 队列容量有限(默认 1000 批次),溢出时丢弃数据
- 进程崩溃导致内存数据全部丢失
- 超过重试时限(默认 5 分钟)后放弃重试
第二层:持久化队列(WAL)
工作原理:基于 Write-Ahead Log 设计,数据进入发送队列前先写入磁盘持久化,确保内存丢失时可重放。
适用场景:
- 下游服务长时间不可用,或 Collector 进程意外崩溃、滚动重启
- 适用于 Gateway、核心业务 Agent 等关键链路 Collector 实例
可靠性收益与局限:
- 进程恢复后可从磁盘重放未成功发送的数据批次
- 依赖磁盘健康与容量,磁盘故障或空间耗尽时仍可能产生数据丢失
第三层:外部消息队列
工作原理:在 Collector 层之间引入 Kafka 等专业消息队列系统,构建高可靠的数据缓冲区。
适用场景:
- 跨网络边界传输(公有云 ↔ 私有数据中心)
- 跨可用区/跨地域容灾
- 对数据可靠性有极端要求的业务场景
可靠性保障:最高级别的数据持久化与可用性,主要风险取决于消息队列自身的配置与运维
WAL 深度剖析
现在让我们深入 WAL 的实现细节,理解其设计思想与工程权衡。
数据结构:改进型 Ring Buffer
WAL 的核心是一个基于 Ring Buffer 思想的持久化队列:
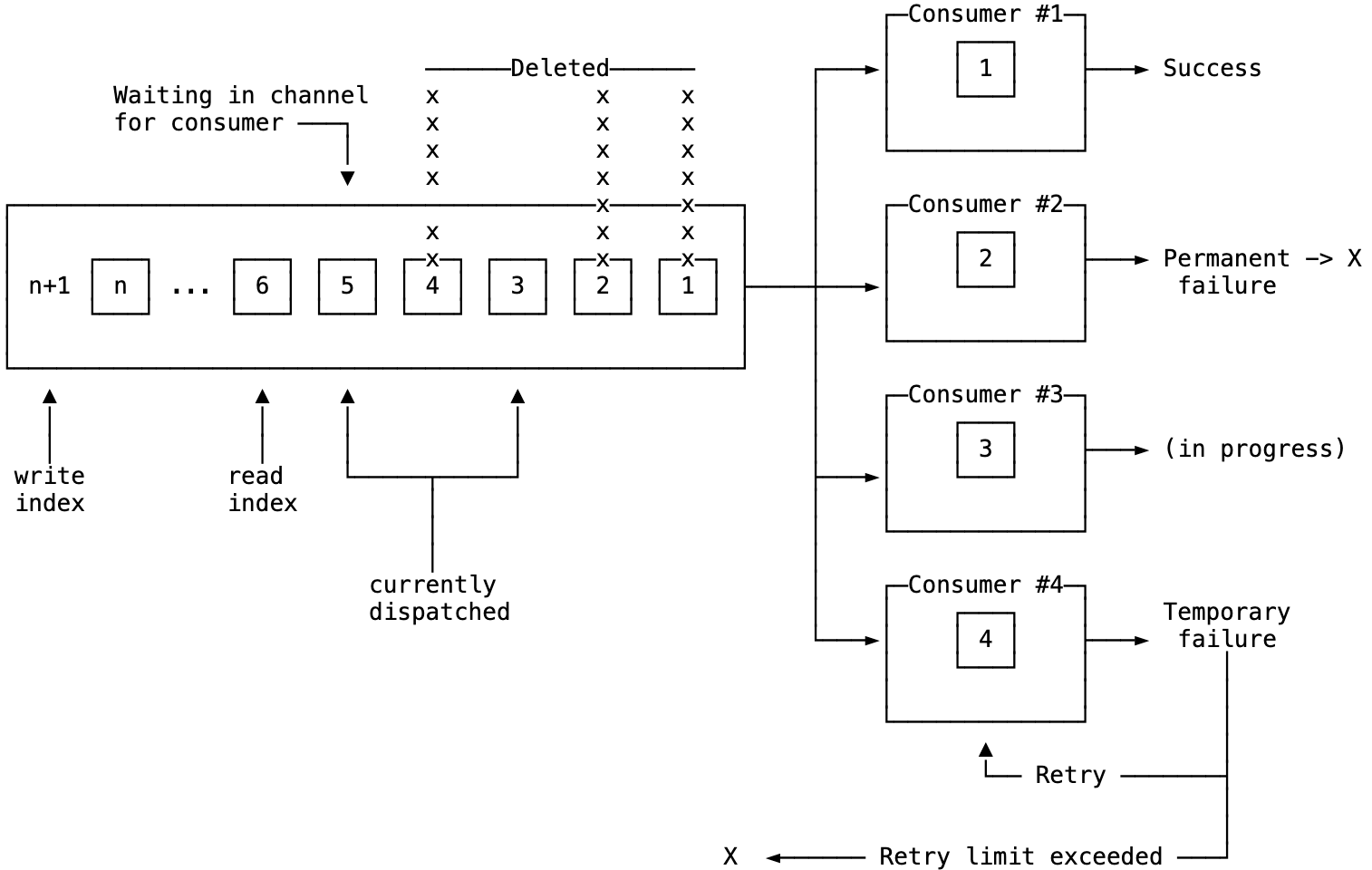
核心属性
capacity:队列最大容量上限read_index:下次读取操作的起始位置write_index:下次写入操作的目标位置currently_dispatched:已出队但尚未确认成功的批次集合size:队列当前实际大小
满空判定机制
队列操作的核心前提是准确判定"空"与"满"两种状态。由于这两种状态下读写指针可能重合,WAL 采用以下策略区分:
判空机制
当 read_index == write_index 时判定队列为空。这是并发环境下最简洁、最可靠的实现方式。空队列时消费者进入阻塞状态等待新数据。
判满机制
维护独立的 size 计数器并持久化,当 size >= capacity 时判定队列已满。计数器在每次读写操作时同步更新,通过互斥锁保证并发安全性。满队列时根据配置选择拒绝新数据或阻塞等待空间释放。
可靠性保障
准确维护 read_index、write_index、size 等元数据的一致性,是确保队列正确性的关键基础。
持久化:bbolt 存储引擎
WAL 选用 bbolt 作为底层存储引擎。bbolt 是 etcd 团队维护的嵌入式键值数据库,具备以下特性:
- 单文件存储,简化部署
- 完整的 ACID 事务支持
- 零外部依赖
- 纯 Go 实现,跨平台兼容
存储结构示意:
// bbolt 数据组织示意
db.Update(func(tx *bolt.Tx) error {
bucket := tx.Bucket([]byte("traces"))
// 元数据键:存储队列状态
bucket.Put([]byte("metadata"), marshalMetadata(metadata))
// 数据键:索引到序列化批次的映射
bucket.Put([]byte("0"), marshalBatch(batch0))
bucket.Put([]byte("1"), marshalBatch(batch1))
// ...
return nil
})
选型理由:
- 运维简单:单文件部署,无需独立进程或额外配置
- 事务保证:Update/View 事务确保操作原子性
- 性能优化:B+ Tree 结构对顺序读写场景友好
- 成熟稳定:etcd 在生产环境中的大规模验证
容量管理:Sizer 机制
如何准确衡量队列"大小"?这是一个需要权衡准确性与性能的工程问题。
方案 1:按批次数量 (request)
sending_queue:
queue_size: 1000 # 限制 1000 个批次
优点:计算开销为 O(1),性能最优
缺点:无法反映真实资源占用。1000 个小批次(每批 10 KB)与 1000 个大批次(每批 1 MB)的资源消耗差异巨大。
方案 2:按数据项数量 (item)
sending_queue:
sizer: item
queue_size: 100000 # 限制 100k 个 spans/metrics/logs
优点:更准确地反映数据规模
缺点:需要遍历批次内的所有数据项,计算复杂度 O(n)
实现示例:
// SpanCount 计算 Trace 数据中的总 span 数
func (ms Traces) SpanCount() int {
spanCount := 0
rss := ms.ResourceSpans()
// 数据结构递进层次:Traces -> ResourceSpans[] -> ScopeSpans[] -> Spans[]
for i := 0; i < rss.Len(); i++ {
rs := rss.At(i)
ilss := rs.ScopeSpans()
for j := 0; j < ilss.Len(); j++ {
spanCount += ilss.At(j).Spans().Len()
}
}
return spanCount
}
方案 3:按字节大小 (bytes)
sending_queue:
sizer: bytes
queue_size: 104857600 # 限制 100 MB
优点:最精确地反映磁盘与内存占用
缺点:需要完整序列化计算,有性能开销
实现示例:
BytesSizer: request.BaseSizer{
SizeofFunc: func(req request.Request) int64 {
tracesReq := req.(*tracesRequest)
// 计算 Protobuf 序列化后的字节大小
return int64(tracesMarshaler.TracesSize(tracesReq.td))
},
}
历史问题:在我们优化之前,由于元数据更新缺乏原子性,bytes 和 items 模式在崩溃恢复后会出现 size 计数错误,导致这两种模式实际不可用。这正是我们要解决的核心问题。
崩溃恢复流程
深入理解崩溃恢复机制,有助于诊断问题根源。
理想恢复流程
// 恢复流程伪代码
func (q *Queue) Recover() {
// 1. 从持久化存储加载元数据
metadata := q.storage.LoadMetadata()
// 2. 恢复队列状态
q.readIndex = metadata.ReadIndex
q.writeIndex = metadata.WriteIndex
q.size = metadata.Size
q.currentlyDispatched = metadata.CurrentlyDispatchedItems
// 3. 重新入队未完成的批次
for _, index := range q.currentlyDispatched {
batch := q.storage.LoadBatch(index)
q.enqueue(batch)
}
}
优化前的关键缺陷
问题 1:元数据非原子更新
元数据的各个字段(read_index、write_index、size、currently_dispatched)分散写入存储,缺乏原子性保证。若在更新过程中崩溃,会导致状态不一致。
问题 2:size 计数器批次持久化
size 计数器并非每次操作都立即持久化,而是按批次写入。这会导致崩溃恢复后计数器与实际数据不一致,容量判断失效。
WAL 机制改进实践
针对 Issue #12890 提出的问题,我们设计并实施了三阶段的系统性优化方案。
阶段一:元数据原子化
核心改进:将 read_index、write_index、size、currently_dispatched_items 统一为单个 QueueMetadata 结构体,更新时整体序列化为一个键值对写入 bbolt。
Protobuf 定义:
// 持久化队列元数据
message PersistentMetadata {
// Sizer 类型枚举 (bytes=0, items=1, requests=2)
int32 sizer_type_value = 1;
// 读指针位置
uint64 read_index = 2;
// 写指针位置
uint64 write_index = 3;
// 队列大小计数器
sfixed64 queue_size = 4;
// 正在处理中的批次索引列表
repeated fixed64 currently_dispatched_items = 5;
}
技术实现:
- 利用 bbolt 事务的原子性保证
- 消除部分写入导致的不一致风险
- 确保崩溃恢复时队列状态与持久化数据严格一致
工程收益:为重新启用精确容量计量(bytes/items 模式)奠定可靠基础
阶段二:平滑版本迁移
工程挑战:如何在不丢失已有 WAL 数据的前提下升级元数据格式?
解决方案:实现向后兼容的迁移逻辑
- 启动时优先尝试加载新格式元数据
- 若检测到旧版本数据,自动逐字段读取并转换为新结构
- 转换完成后清理旧键值对
- 整个流程对用户透明,无需人工干预
代码示意:
func (pq *persistentQueue[T]) initClient(ctx context.Context) {
// 优先加载新格式元数据
err := pq.loadQueueMetadata(ctx)
switch {
case err == nil:
// 新格式加载成功,恢复未完成的请求
pq.recoverDispatchedItems(ctx)
case !errors.Is(err, errValueNotSet):
// 加载失败(非键不存在),记录错误并重置
pq.logger.Error("Failed to load metadata", zap.Error(err))
pq.resetMetadata()
default:
// 新格式不存在,尝试从旧版本迁移
pq.migrateFromLegacyFormat(ctx)
}
}
工程收益:已部署的 Collector 实例升级后自动迁移 WAL 数据,避免因格式不兼容导致的数据丢失
阶段三:全 Sizer 模式支持
工程挑战:当用户切换 sizer 配置时,如何从持久化存储中恢复对应的队列大小?
解决方案:同时计算并持久化三种模式的队列大小
Protobuf 最终定义:
// 持久化队列元数据
// request 大小可通过公式计算:
// (write_index - read_index + len(currently_dispatched_items))
message PersistentMetadata {
// 队列中的数据项
sfixed64 items_size = 1;
// 队列中的数据总字节数
sfixed64 bytes_size = 2;
// 读指针位置
fixed64 read_index = 3;
// 写指针位置
fixed64 write_index = 4;
// 正在处理的批次索引列表
repeated fixed64 currently_dispatched_items = 5;
}
技术权衡:
- 增加计算开销:每次入队/出队时需计算三种指标
- 提升灵活性:用户可随时切换
sizer类型,无需重建 WAL - 确保准确性:崩溃恢复后立即恢复正确的队列状态
配置示例:
exporters:
otlp:
endpoint: https://backend.example.com
sending_queue:
enabled: true
storage: file_storage
queue_size: 1000
sizer: item # 可选:request | item | bytes
extensions:
file_storage:
directory: /var/lib/otelcol/data
timeout: 10s
compaction:
on_start: true
工程收益:用户可根据磁盘容量、数据特征灵活选择最适合的容量计量方式,实现更精细的资源控制
改进成效总结
可靠性提升
解决了 WAL 崩溃恢复场景下的元数据一致性问题,显著降低了数据丢失风险
功能增强
使 bytes 和 items 类型的 Sizer 真正可用,提供了更精准的资源管理能力
社区影响
相关改进已随 OpenTelemetry Collector v0.130.0 正式发布,惠及全球用户
工程经验
- 元数据原子性是持久化队列可靠性的基石
- 向后兼容的迁移策略对生产环境至关重要
- 性能与准确性的权衡需要根据实际场景灵活选择
Collector 可靠性配置最佳实践
基于实践经验与社区最佳实践,我们总结以下配置建议:
1. 始终启用发送队列
对于通过网络发送数据的 Exporter,这是基础要求。即使不启用 WAL,内存队列也能提供基本的重试能力。
exporters:
otlp:
sending_queue:
enabled: true
queue_size: 5000
2. 主动监控关键指标
配置 Prometheus 采集 Collector 自身指标,重点关注:
otelcol_exporter_queue_size:当前队列大小otelcol_exporter_queue_capacity:队列容量上限otelcol_exporter_send_failed_spans:失败的 span 数量
提前发现队列溢出与数据丢失风险。
3. 分层部署架构
采用 Agent + Gateway 的分层架构:
- Agent 层:轻量级处理,快速转发
- Gateway 层:集中式复杂处理、批处理、WAL 持久化
将主要的可靠性机制集中在 Gateway 层或关键网络跳跃点上。
4. 按需启用 WAL
并非所有 Collector 实例都需要启用 WAL:
- 推荐启用:Gateway 层、关键业务数据链路的 Agent
- 避免启用:同节点上 SDK 到 Agent 的可靠本地回环链路
5. 谨慎引入消息队列
外部消息队列适用于以下场景:
- 跨网络边界或跨可用区的数据传输
- 需要解耦 Collector 层依赖关系
- 对数据可靠性有极端要求的核心业务
同时需要权衡:
- 增加的运维复杂度(部署、监控、容量规划)
- 引入的额外延迟
- 消息队列自身的可靠性保障
结语
OpenTelemetry Collector 作为可观测性架构的核心枢纽,其可靠性机制的设计直接影响整个系统的数据质量。本文从架构原理出发,深入剖析了 WAL 持久化队列的实现细节,并分享了我们针对元数据一致性问题的系统性优化实践。
通过元数据原子化、平滑版本迁移、全 Sizer 模式支持三阶段的改进,我们不仅解决了崩溃恢复场景下的数据一致性问题,还为用户提供了更灵活、更精准的容量管理能力。这些改进已随 OpenTelemetry Collector v0.130.0 正式发布,并在生产环境中得到验证。
希望本文能够帮助读者深入理解 Collector 的内部机制,在实际项目中更好地利用其可靠性特性。欢迎在社区中分享您的实践经验与反馈!
参考资料
- OpenTelemetry Collector Docs
- ETCD Bbolt Github
- OpenTelemetry Collector Issue #12890
- OpenTelemetry Collector Scaling
- CNCF Projects - OpenTelemetry
本文内容基于 OpenTelemetry Collector v0.130.0